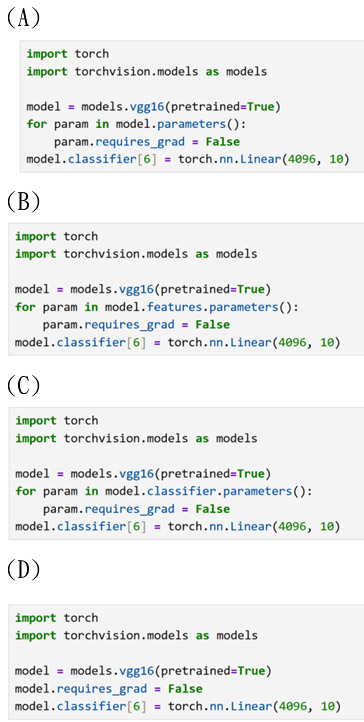
38. 附圖程式碼所計算的是哪一類型的評估指標?

(A) MAE;
(B) MSE;
(C) RMSE;
(D) R²
看解答
(B) MSE;
(C) RMSE;
(D) R²
正確答案是 (B) MSE。
這題考驗的是機器學習中迴歸模型(Regression Model)最經典的評估指標——均方誤差(Mean Squared Error, MSE)。
我們可以將附圖中的 Python 程式碼公式與數學公式進行一對一的拆解:
• (y_true - y_pred):計算誤差(Error),即「真實值」與「預測值」之間的差距。
• 在 Python 中,**2 代表平方(Squared),也就是將誤差進行平方。這有兩個核心作用:
消除正負號的影響(避免正負誤差互相抵消)。
放大較大誤差的懲罰權重。
• sum(...):將所有樣本的誤差平方加總(\(\sum\))。
• / len(y_true):除以樣本的總數量,也就是計算平均(Mean)。
將以上步驟結合成數學公式,就是標準的 MSE 公式:
$$\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_{\text{true}} - y_{\text{pred}})^2$$
其他選項的程式碼寫法對照:
為了更清晰地理解差異,我們來看看其他三個迴歸指標在 Python 中會如何寫:
(A) MAE(平均絕對誤差,Mean Absolute Error):
特徵: 不用平方,而是取絕對值。
程式碼: return sum(abs(y_true - y_pred)) / len(y_true)
(C) RMSE(均方根誤差,Root Mean Squared Error):
特徵: 在 MSE 的計算結果外面,再加上開根號(Square Root)。
程式碼: return (sum((y_true - y_pred)**2) / len(y_true))**0.5
(D) \(R^2\)(決定係數,Coefficient of Determination):
特徵: 用來評估模型解釋資料變異量的比例,公式較為複雜,分母需要包含真實值的總平方和(TSS)。
迴歸指標核心定義速記
| 指標縮寫 | 全名 | 核心數學特徵 | 英文直譯記憶法 |
|---|---|---|---|
| MAE | Mean Absolute Error | 使用 abs() 取絕對值 | 平均 ➔ 絕對 ➔ 誤差 |
| MSE (B) | Mean Squared Error | 使用 ** 2 取平方 (B) | 平均 ➔ 平方 ➔ 誤差 (B) |
| RMSE | Root Mean Squared | 平方後再開根號 ** 0.5 | 根 ➔ 平均 ➔ 平方 ➔ 誤差 |
解題關鍵:在機器學習的程式碼考題中,只要看到 (y_true - y_pred)**2(誤差的平方)外層套著 sum(...) / len(...)(求平均),這在定義上就是 Mean(平均)Squared(平方)Error(誤差)。看到關鍵字 Squared,即可瞬間秒殺選擇 (B) MSE。