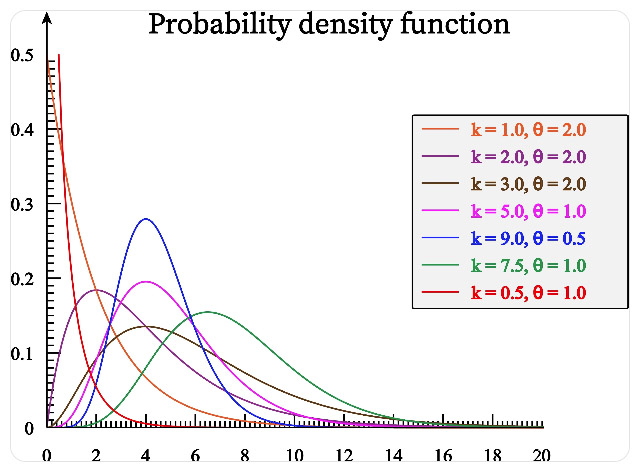
3. 附圖為某資料之分佈圖,此圖資料之偏態(Skewness)值較有可能為下列哪個選項?
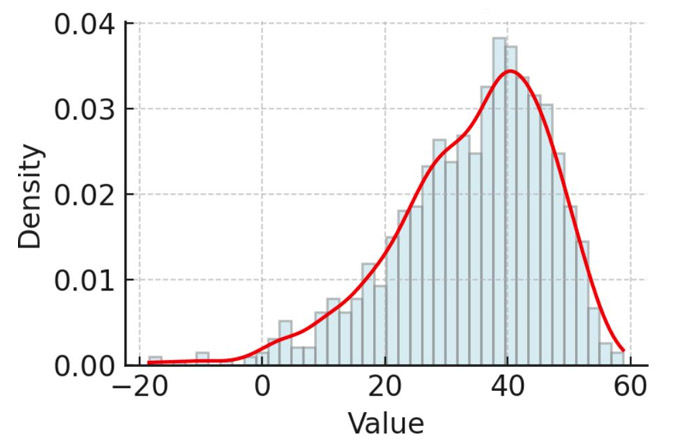
(A) Skewness < 0;
(B) Skewness > 0;
(C) Skewness = 0;
(D) 無法計算 Skewness
看解答
(B) Skewness > 0;
(C) Skewness = 0;
(D) 無法計算 Skewness
正確答案是 (A) Skewness < 0。
這題考驗的是如何透過資料的次數分配圖(直方圖與密度曲線)來判斷統計學中的 偏態(Skewness) 類型。
(A) 為正確答案:
觀察圖形特徵: 從附圖中可以明顯看出,資料的最高峰(眾數)集中在右側(約在 40 附近),而圖形的尾巴(Tail)明顯向左側(負數方向)延伸。
左偏分佈(Left-skewed / Negatively skewed): 當資料分佈的尾巴拉向左側時,在統計學上被稱為「左偏」或「負偏」。
偏態值的正負號: 左偏分佈的偏態值(Skewness)必然小於 0(\(Skewness < 0\))。這是因為左側長尾巴上那些極端小的數值(如圖中的 \(-20\) 到 \(0\)),會把算術平均數往左邊拉。
(B) 錯誤:
若 \(Skewness > 0\),稱為右偏分佈(Right-skewed / Positively skewed),圖形的尾巴應該要向右側(正數方向)無限延伸,高峰則會偏向左側。
(C) 錯誤:
若 \(Skewness = 0\),代表資料為完全對稱分佈(例如標準常態分佈),左右兩側的尾巴長度和下降坡度會完全一致。
(D) 錯誤:
只要資料是一組連續型的數值型數據,並且知道其平均數、中位數與標準差,就可以透過三階動差公式明確計算出 Skewness。
三種偏態分佈核心特徵對比
| 分佈類型 | 尾巴延伸方向 | 平均數、中位數、眾數的大小關係 | 偏態值 (Skewness) |
|---|---|---|---|
| 左偏分佈(本題圖形) | 向左(負向)延伸 | 平均數 \(<\) 中位數 \(<\) 眾數 | \(Skewness < 0\) (A) |
| 對稱分佈 | 左右完全對稱 | 平均數 \(=\) 中位數 \(=\) 眾數 | \(Skewness = 0\) |
| 右偏分佈 | 向右(正向)延伸 | 眾數 \(>\) 中位數 \(>\) 平均數 | \(Skewness > 0\) |
解題關鍵:判斷偏態時,切記一句口訣:「尾巴在哪裡,就往哪裡偏」。 看圖時不要看最高峰,而是要看那條紅線被拉長的尾巴。這張圖的尾巴一路往左邊的負數跌落,所以它是左偏(又稱負偏),負偏的 Skewness 自然就小於 0。